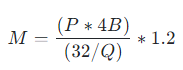
该公式只需对变量P和Q进行替换即可。
目前模型的参数绝大多数都是float32类型, P * 4B(B表示Bytes) 表示模型对应的参数的字节数, 而1GB刚好等于10亿字节,因此这部分实际上是包含单位在内的换算。
当模型加载的权重精度为FP8或FP16时,Q=8或16,由于每个参数本来需要32bit,因此当采用低精度加载时,内存只需要原来的1/4 或 1/2, 也即1/(32/Q)。
以Qwen2-7B-Instruct为例,其参数总字节数为:(7*10亿) * 4 Bytes,
换算为GB: ((7*10亿) 4 Bytes ) / 10亿 Bytes = 7 4 GB = 28GB,
当Q=8时, M= (28GB/(32/8) ) * 1.2 = 8.4GB。
在实际估算中,可以省去上述复杂过程,直接替换P与Q的数值,使用下述在线工具估算:
https://huggingface.co/spaces/hf-accelerate/model-memory-usage